[DB] 인덱스에 대해 알아보자
인덱스란 데이터베이스에서 조회 및 검색을 빠르게 할수있는 기술 혹은 자료구조를 의미한다.
먼저, 인덱스가 생겨나게 된 배경에 대해 이해해보자.
테이블의 물리적 저장구조
- 우리가 만든 테이블의 투플은 저장공간(하드디스크, 플래시메모리)에 Heap file또는 Sorted file형태로 저장된다.
- heap file : 투플들이 무순서로 저장됨. insert비용은 낮지만 검색비용이 높다.
- Sorted file : 테이블의 특정 컬럼값의 순서대로 투플이 저장됨 → 해당 애트리뷰트로 검색할때 효율적이다.O(logN)
- ex) 학생테이블에서 학번순으로 sorting되어있는경우 이분탐색으로 로그엔시간에 탐색이 가능. 문제점 : 이름으로 검색하는경우?! → 인덱스가 필요한 이유
인덱스의 필요성
Student테이블에서 투플이 기본키인 sno순으로 저장되어있다고 가정하자.
아래와 같은 두 쿼리를 보면 이름으로 검색하는 경우 해당 컬럼의 입장에서는 데이터의 물리적 저장구조가 정렬되지 않은 형태일것이다.
따라서 이분탐색과같은 효율적인 탐색 알고리즘을 사용할 수 없고 그저 순차탐색을 해야하는 상황이 발생한다.
그래서 생겨난것이 인덱스이다.
select * from student where sno = 1234; --sno로 검색 -> 빠름select * from student where sname = '이승진'-- 이름으로 검색 -> 힙파일과 다를바가 없음!인덱스
테이블에 저장한 애트리뷰트값에 대하여 Tree혹은 Hash형태의 보조적인 저장구조로 해당 애트리뷰트에 대한 검색을 빠르게 해주는 기술?장치?이다.
즉, 자주 조회되는 Column 에 대한 Index Table을 따로 만들어 SELECT 문이 들어왔을 때 Index 테이블에 있는 값들로 결과 값을 조회해 온다.
그래서 Index를 잘 사용한다면 검색 연산을 실행했을 때 성능을 올릴 수 있게 된다.
인덱스의 종류
- Primary VS Secondary : 인덱스 키가 PK를 포함하고 있다면 primary index이다.
- Clustered VS unclusterd : 데이터 레코드의 순서가 인덱스 엔트리의 순서와 같으면 클러스터 인덱스이다.

- DBMS는 레코드를 하나씩 읽지않고 page(레코드의 집합)단위로 읽는다.
- DBMS의 성능은 CPU나 메모리 성능보다 디스크접근비용에 좌우된다. ( 즉 그만큼 적은 디스크접근을 해야 성능이 좋아진다는것)
- range search(범위검색)의 경우, 클러스터 인덱스에서는 범위안에있는 page갯수만큼 디스크를 접근하지만 unclustered 인덱스의 경우, worst case 해당범위의 레코드수만큼 디스크를 접근하게된다.
단, 클러스터 인덱스는 테이블당 하나만 존재할 수 있다. 당연한것 (data records의 순서와 동일한것은 하나밖에 만들수 없으니까)
MySQL의 경우 PK가 이미 클러스터 인덱스를 독점하고있다. 즉 어떤 테이블에서 PK를 설정했다는것은 이미 그 PK로 클러스터 인덱스가 만들어졌다는것을 의미한다.
인덱스의 동작방식
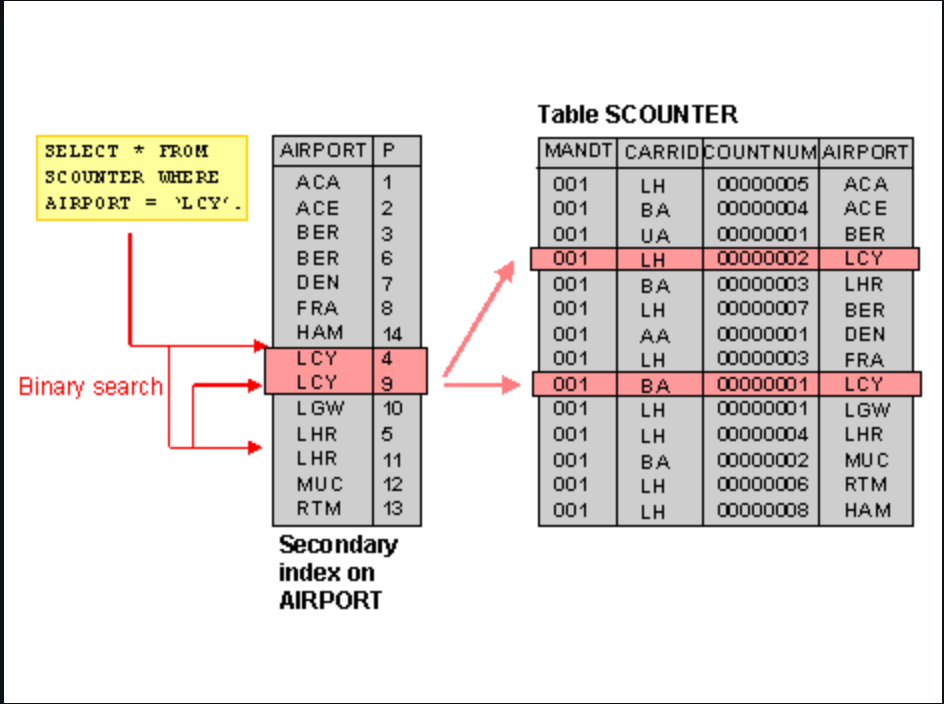
- Index Table에서 where에 포함된 값을 검색
- 해당 값의 table_id PK를 획득
- 가져온 table_id PK값으로 원본 테이블에서 값을 조회
B+ Tree 알고리즘
B+ 트리 알고리즘은 인덱스를 구성하는데 사용되는 알고리즘이다.

- 실제 데이터가 저장된 리프노드(Leaf nodes)
- 리프노드까지의 경로 역할을 하는 논리프노드(Non-leaf nodes)
- 경로의 출발점이 되는 루트 노드(Root node)
B+tree는 균형트리이기 때문에 데이터의 삽입/삭제에도 균형이 유지된다. ( 리프노드가 같은 레벨에 존재하도록 유지된다)
O(logfM) (밑이 f) 의 탐색시간복잡도를 갖는다. 이때 f는 자식노드의 갯수이다.
예를들어 f가 100인경우 100억개의 data records에 대한 tree_depth는 겨우 5밖에 안된다!! (편향적으로 트리가 구성되지 않도록 보장된다는것)
즉, B+트리의 검색은 루트노드에서 어떤 리프 노드에 이르는 한 개의 경로만 검색하면 되므로 매우 효율적이다.
그럼 인덱스 생성시 왜 B+ tree를 사용하는가? 그냥 해시테이블을 사용해서 키-값으로 매핑하면 되지 않는가??
- SELECT 질의 조건에는 부등호 연산(<>)도 포함
- hash table은 동등 연산에 특화된 자료구조이기 때문에 부등호 연산 사용 시 문제 발생
위와같은 이유로 대부분 해시자료구조보다는 B+ Tree를 사용한다. (range search의 한계)
어떤컬럼을 인덱스로 사용해야하는가
인덱스를 무작정 생성하는것이 성능향상을 보장해주지 않는다. 따라서 인덱스를 잘 알고 이해해서 어떤 컬럼에 대해 인덱스를 설정할것인지가 중요하다.
예를들어보자.
어떤 테이블에서 99%이상의 사람이 40살이라고 할때 age를 인덱스로 설정하는것이 성능향상에 도움이될까?
select dno from e where age > 40;반대로 10%이상이 40살 이상이다.
그럴때 age를 인덱스로 설정하면 도움이 될까?
이는 인덱스가 unclustered냐 clustered냐에 따라 다르다.
- 만약 unclustered인덱스라면 그냥 순차탐색보다 더 안좋은 성능을 보일 수 있다. (범위탐색과 관련해서 생각하면 당연하다.최악의경우 순차탐색과 같은횟수만큼 데이터레코드를 읽어야하고 굳이 인덱스를 설정할 필요가 없기때문)
- 인덱스가 클러스터냐 아니냐에 따라 다르다.
일반적으로는
- where조건의 대상이되는것들은 인덱스의 후보가 될 수 있다.
- multi-attribute도 하나의 인덱스가 될 수 있다.
- 자주쓰는 쿼리를 인덱스의 대상으로 한다.
- 클러스터 인덱스는 하나밖에 존재할 수 없기때문에 가장 자주쓰이는 것을 대상으로 한다.
인덱스 사용시 주의할점 (단점)
- 무분별한 인덱스는 지나치게 많은 테이블을 생성하게 된다.
- 인덱스는 따로 테이블의 형태로 관리가 된다. 때문에 무분별한 인덱스의 사용은 메모리적으로 낭비를 가져올 수 있음!
- 인덱스는 검색/조회에는 아주 좋은 성능 but 빈번한 삽입/삭제/수정에는 트리구조에 의한 정렬유지등과 같은 오버헤드가 발생한다.
- 인덱스는 이진트리를 사용하기 때문에 기본적으로 정렬되어 있다. 이로인해 검색과 조회의 속도를 향상시킬 수 있지만 잦은 데이터의 변경(삽입, 수정 삭제)가 된다면 인덱스 테이블을 변경과 정렬에 드는 오버헤드 때문에 오히려 성능 저하가 일어날 수 있다.
- INSERT : 테이블에는 입력 순서대로 저장되지만, 인덱스 테이블에는 정렬하여 저장하기 때문에 성능 저하 발생
- DELETE : 테이블에서만 삭제되고 인덱스 테이블에는 남아있어 쿼리 수행 속도 저하
- UPDATE : 인덱스에는 UPDATE가 없기 때문에 DELETE, INSERT 두 작업 수행하여 부하 발생
- 인덱스는 이진트리를 사용하기 때문에 기본적으로 정렬되어 있다. 이로인해 검색과 조회의 속도를 향상시킬 수 있지만 잦은 데이터의 변경(삽입, 수정 삭제)가 된다면 인덱스 테이블을 변경과 정렬에 드는 오버헤드 때문에 오히려 성능 저하가 일어날 수 있다.
- 데이터의 중복이 높은 컬럼(카디널리티가 낮은 컬럼)은 인덱스로 만들어도 무용지물 (예: 성별) → 어차피 남여 반반으로밖에 못나누고 대부분이 여자일수 있는데 인덱스를 활용하는 이유가 없다.
- 다중 컬럼 인덱싱할 때 카디널리티가 높은 컬럼->낮은 컬럼 순으로 인덱싱해야 효율적
데이터베이스의 성능을 좌우하는 요소
- DB설계자 관점
- 테이블의 저장구조 : 어떤 에트리뷰트순으로 소팅할것인가,
- 인덱스 : 검색성능 (해시, 비트리)
- DBMS 성능관점
- 물리적연산자
- 질의 최적화테이블의 물리적 저장구조